Building EcoVeridian (v1.0.0)
Documenting the process and the tech stack
I've spent the last few months building something I've wanted to exist for a long time: a way to instantly see how "green" a company actually is when I'm browsing their website. Not their marketing fluff, but their real ESG (Environmental, Social, Governance) data.
If you're here just for the technical breakdown, scroll down to "The Stack". But if you want to know why I built this thing, keep reading.
The Problem
Every company these days has a "sustainability" page. A bunch of stock photos of wind turbines, promises about "net-zero by 2050," and vague language about "commitment to the planet." It's all performative garbage.
I wanted to know: Is Nike actually sustainable, or are they just good at marketing? What about Amazon? Tesla? That random DTC brand I'm about to buy from?
The data exists. ESG reports, carbon footprint analyses, labor practice audits. It's all out there. But it's scattered across press releases, third-party reports, and industry databases. Nobody's aggregating it in real-time while you browse.
So I built EcoVeridian.
What It Does
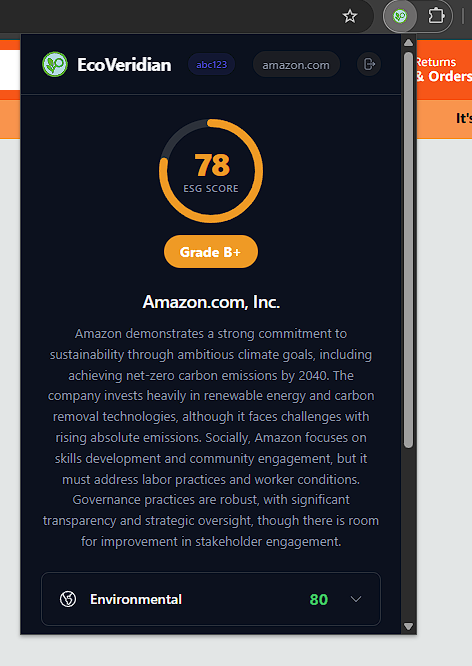
Dead simple: You click the extension icon. It tells you how green the company actually is.
![]()
The extension:
- Grabs the domain you're on (e.g.,
nike.com) - Sends it to my backend API
- Runs it through my proprietary scoring pipeline
- Returns an Eco-Score (0-100), a letter grade, and a full ESG breakdown
The whole thing takes ~3-5 seconds. If the company's been analyzed before, it's instant (cached for 30 days).
The Stack
Frontend (Chrome Extension)
- React 19
- Vite 7
- TypeScript 5.9
- Chrome Manifest V3
Backend (Cloud Functions)
- Node.js 24
- Firebase Cloud Functions (Gen 2)
- Firestore
- TypeScript
The "Engine" (This Is Where It Gets Interesting)
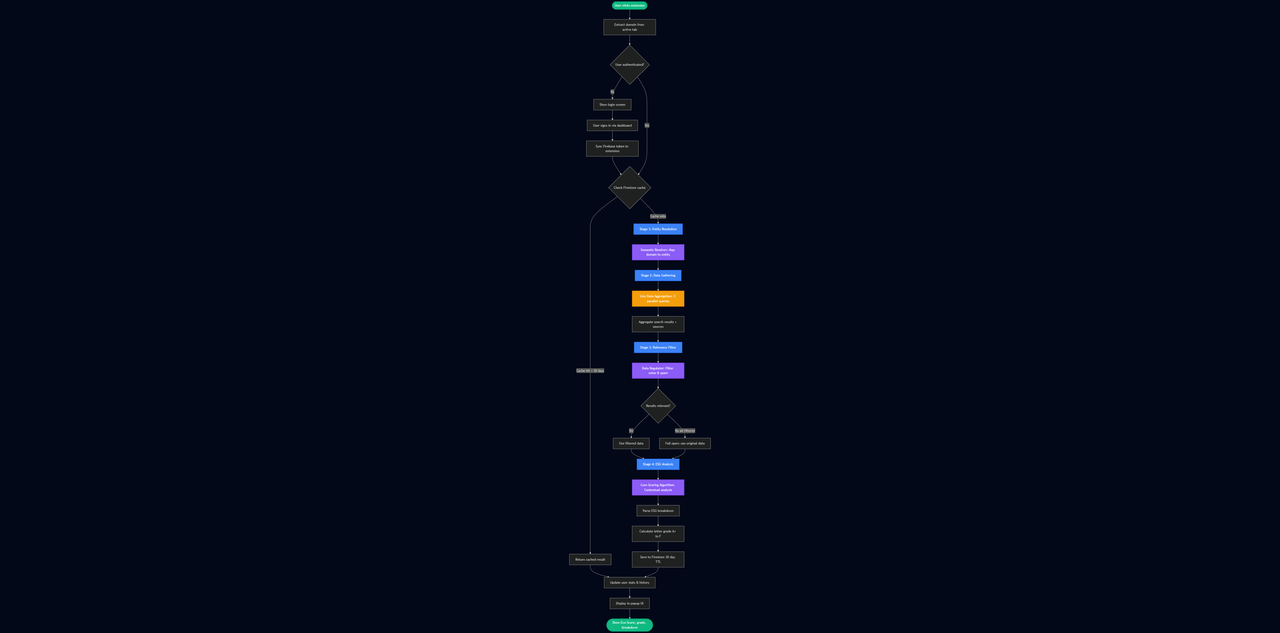
Here's the part I'm most proud of. The backend doesn't just call a database and call it a day. It's a 3-stage processing pipeline designed to be cost-efficient and accurate:
Stage 1: Company Identification (Entity Resolution Layer)
The extension sends me a domain like nike.com. I need to know if that's Nike Inc., Nike Energy Solutions, or some random blog.
I run this through a lightweight semantic resolver. It's optimized for speed and does one thing: maps the URL to the official corporate entity. Simple lookup task = low compute cost.
Stage 2: Data Gathering (Tavily API)
Once I know the company, I fire off 3 search queries to Tavily (a search API built for automated agents):
"Nike Inc sustainability report ESG environmental""Nike Inc carbon footprint climate initiatives""Nike Inc corporate social responsibility labor practices"
Tavily scrapes the web and returns the top results + content snippets.
Stage 3: Relevance Filtering (The Semantic Regulator)
Here's the problem: search results are noisy as hell. If I search for "Apple sustainability," I'll get results about Apple Inc., but also apple orchards, Apple Music's energy usage, random blog spam, etc.
So I built a Data Regulator. It reads each search result and runs a relevance check: "Is this about the company we're researching, or is it garbage?"
It filters out:
- Different companies with similar names
- Generic industry news
- Ads and spam
- Unrelated topics (e.g., fruit recipes when researching Apple Inc.)
Stage 4: ESG Scoring Engine (Contextual Analysis)
Now I have clean, relevant data. Time for the big guns: The Core Scoring Algorithm.
I feed the filtered data into a large-context reasoning engine configured with a strict auditing rule set:
- Analyze the company's ESG practices against known standards
- Assign scores (0-100) for Environmental, Social, and Governance
- Calculate an overall Eco-Score
- Extract highlights and concerns for each category
- Summarize in 2-3 sentences
This process is computationally expensive, but it's worth it for complex reasoning. I force the engine to output structured JSON so the response is always parseable. No janky regex parsing of arbitrary text.
The Frontend (Extension UI)
The popup is intentionally minimal. You click the icon, you see:
- Company name (top)
- Eco-Score (big number, 0-100)
- Letter Grade (A+ to F)
- Summary (2-3 sentences)
- Breakdown (Environmental, Social, Governance tabs)
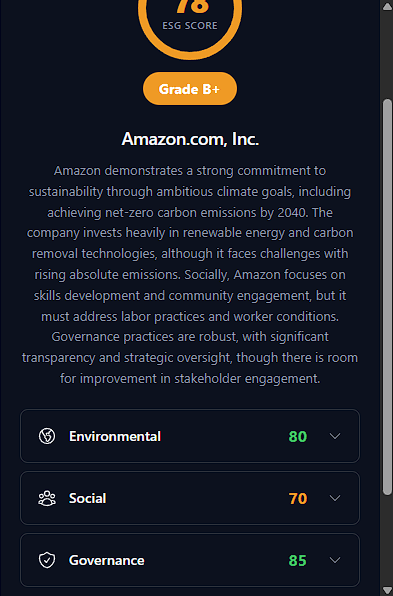
The color scheme is:
- Green (70+) = Good
- Yellow (50-69) = Meh
- Red (<50) = Bad
Firebase Authentication
The extension requires you to have an account to be able to use it. This is because I want to be able to:
- Rate Limit – Without auth, anyone could spam my API and drain my money.
- User History – Signed-in users get a history of analyzed companies (stored in Firestore).
- Stats Tracking – I track total sites analyzed, average scores, etc. (anonymized, no PII).
What I'd Do Differently (Lessons Learned)
1. Parsing Unstructured Data Is Hard
My "Regulator" layer is fast, but handling unstructured web data is way less reliable than I'd like. Sometimes the upstream data comes back as perfect JSON. Sometimes it returns markdown with the data buried inside. Sometimes it just... fails to format correctly.
I had to add fallback parsing logic:
const jsonMatch = responseText.match(/\[.*\]/s);
if (!jsonMatch) {
console.warn("Regulator failed, returning original results");
return originalResults;
}
Always fail open! Never trust external data inputs to be consistent.
2. Firestore Is Expensive (At Scale)
Right now, with low traffic, Firestore is fine. But if this blows up, I'm gonna get wrecked by read/write costs. Each query writes to cache + user history = 2 writes. Each cache hit = 1 read.
If I hit 10k daily users, that's ~$50-100/month in Firestore costs alone. I might migrate to Postgres or Redis if that happens.
Universal Support
Right now, EcoVeridian only works on Chrome (and Chromium-based browsers like Edge, Brave, etc.).
Firefox support is in development. The extension uses Manifest V3, which Firefox technically supports, but their implementation is... different. I need to:
- Rewrite parts of the service worker (Firefox handles them differently)
- Test on actual Firefox (not just MDN docs)
I'm one person. I prioritized Chrome because it's 65% of the market. Firefox is coming, but it's not here yet. (I'm a Firefox user myself ˙◠˙ ).

Closing Thoughts
I'm actually really proud of how this turned out. It’s a solid v1.0.0. Handling unstructured web data is messy, but the pipeline holds up. The UI is minimal and gets out of your way, which was the goal from day one.
And it works. I built the entire thing myself: frontend, backend, deployment, everything.
If you use this and find a company that scores way higher or lower than you expected, send me a message. I'm always tweaking the scoring algorithm to be sharper.
The goal here is transparency. Companies spend millions on green marketing to make you think they care. EcoVeridian checks the receipts. It turns hours of digging through dense reports into a 3-second reality check.
If you're like me and you want to know exactly who you're supporting before you give them your money? Yeah, this is the tool I wish I had years ago.
